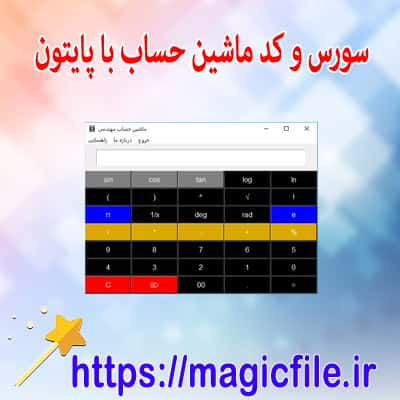

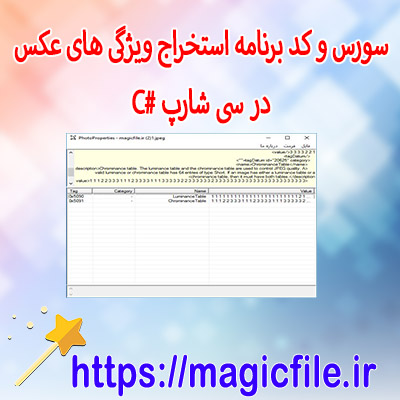

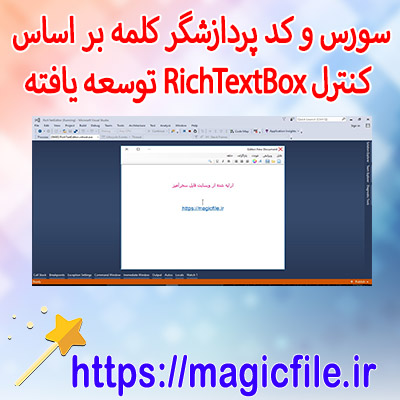

دیتابیس داده های فارسی
دَرباره دیتابیس دادههای فارسی
دیتابیس دادههای فارسی، به مجموعهای از اطلاعات و دادهها اطلاق میشود که به زبان فارسی ذخیره و پردازش میشوند. این دیتابیسها میتوانند شامل متون، تصاویر، صوت و ویدیو باشند که به طور خاص برای کاربران فارسیزبان طراحی شدهاند.
به طور کلی، دیتابیسهای دادههای فارسی در حوزههای مختلف کاربرد دارند. از جمله:
- تحقیق و توسعه: محققان نیاز دارند تا به دادههای معتبر و موثق در زبان فارسی دسترسی داشته باشند. این دادهها میتوانند شامل مقالات علمی، کتابها و مطالعات موردی باشند.
- تحلیل دادهها: شرکتها و سازمانها از دیتابیسهای فارسی برای تحلیل رفتار مشتریان و نیازهای بازار استفاده میکنند. این تحلیلها به تصمیمگیریهای استراتژیک کمک میکند.
- محصولات دیجیتال: نرمافزارها و برنامههای موبایلی که به زبان فارسی طراحی شدهاند، نیازمند دیتابیسهای مناسب برای ذخیرهسازی اطلاعات کاربران هستند.
چالشها و فرصتها
در این راستا، چالشهایی نیز وجود دارد. به عنوان مثال، عدم دسترسی به منابع معتبر و زبانشناسی مناسب میتواند مشکلاتی را ایجاد کند. همچنین، نیاز به پردازش زبان طبیعی (NLP) برای بهبود تعاملات کاربری و فهم دادهها بسیار حائز اهمیت است.
از سوی دیگر، فرصتهای زیادی نیز به وجود آمده است. با پیشرفت فناوریهای اطلاعات و ارتباطات، امکان ایجاد و بهروزرسانی دیتابیسهای دادههای فارسی به صورت مداوم فراهم شده است. این امر به کاربران کمک میکند تا به اطلاعات بهروز و موثق دسترسی داشته باشند.
نتیجهگیری
در نهایت، توسعه و مدیریت دیتابیسهای دادههای فارسی، نه تنها به ارتقاء کیفیت اطلاعات موجود کمک میکند، بلکه میتواند به ایجاد فرصتهای جدید در زمینههای مختلف منجر شود. به همین دلیل، توجه به این موضوع و سرمایهگذاری در آن بسیار ضروری است.
استمینگ به منظور ارزیابیداده های فارسی استمینگفارسی استیمینگفارسی استیمینگ چیستلیست کلمات استمینگمجموعه داده های فارسی استمینگدیتابیس داده های فارسیمجموعه داده های استمینگداده های فارسیاستمینگ داده هادیتابیس فارسیدانلود دیتابیس استمینگپروژه داده های فارسیتحلیل داده های فارسیداده کاوی در فارسیزبان فارسی در داده ها
توضیحات درباره دیتابیس مجموعه دادههای فارسی استمینیگ
دیتابیس مجموعه دادههای فارسی استمینیگ یک منبع ارزشمند برای پژوهشگران، توسعهدهندگان و علاقهمندان به پردازش زبان طبیعی (NLP) است. این دیتابیس شامل مجموعهای از دادههای متنی است که به منظور تحلیل و پردازش زبان فارسی طراحی شدهاند.
این مجموعه دادهها به کاربران این امکان را میدهد که در پروژههای مرتبط با یادگیری ماشین، مدلسازی زبان و تحلیل متن استفاده کنند. به طور خاص، این دیتابیس میتواند در زمینههای مختلفی از جمله شناسایی احساسات، ترجمه ماشینی و تولید متن کاربرد داشته باشد.
ویژگیهای کلیدی
- دادههای متنوع: این دیتابیس شامل انواع مختلف دادههای متنی از منابع گوناگون است. از جمله مقالات، وبسایتها و محتوای اجتماعی.
- ساختار منظم: دادهها به صورت منظم و دستهبندی شده در دسترس هستند که جستجو و استفاده از آنها را سادهتر میکند.
- قابلیت مقیاسپذیری: کاربران میتوانند به راحتی از این دیتابیس در پروژههای بزرگ خود استفاده کنند و آن را گسترش دهند.
کاربردها
این دیتابیس برای محققان و دانشجویان در حوزههای مختلف مانند علوم کامپیوتر، زبانشناسی و هوش مصنوعی بسیار مفید است. همچنین، توسعهدهندگان نرمافزار میتوانند از این دادهها برای بهبود الگوریتمهای خود و ساخت مدلهای قویتر استفاده کنند.
در نهایت، این دیتابیس به عنوان یک منبع منحصربهفرد در زمینه پردازش زبان فارسی، میتواند به پیشرفتهای قابل توجهی در این حوزه منجر شود.
یک فایل در موضوع (دانلود دیتابیس مجموعه داده های فارسی استمینگ به منظور ارزیابی) آماده کرده ایم که از لینک زیر می توانید دانلود فرمایید برای دانلود کردن به لینک زیر بروید

منبع : https://magicfile.ir
- یکشنبه ۲۱ اردیبهشت ۰۴ ۰۹:۴۷ ۱۶۶ بازديد
- ۰ نظر